
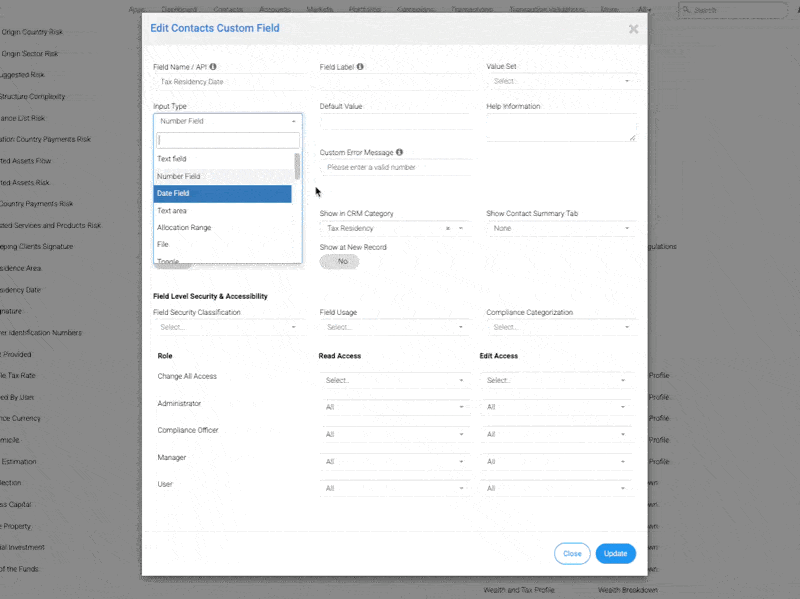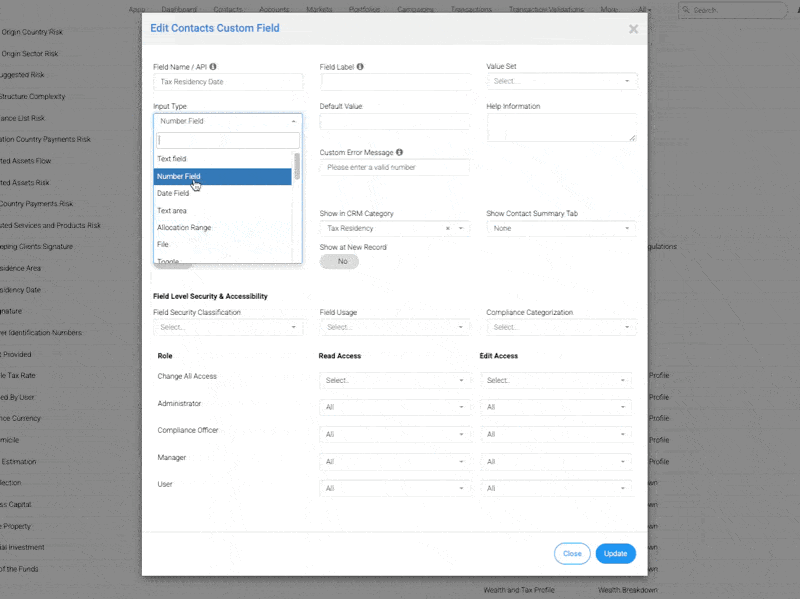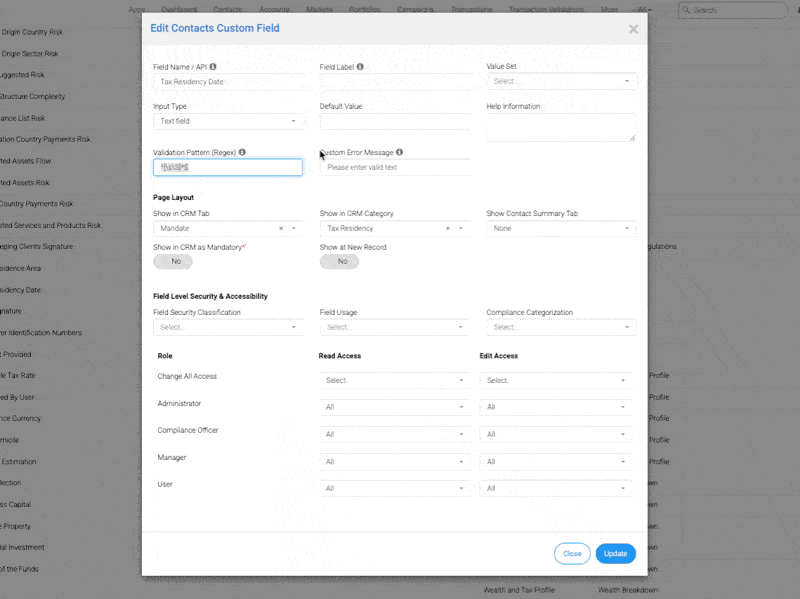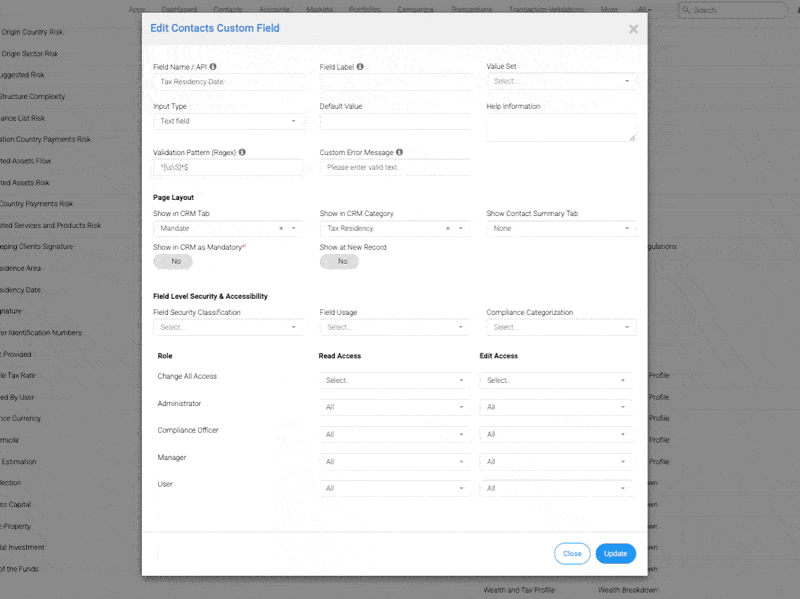
Hvorfor REGEX er vigtig i CRM
InvestGlass er stolt af at kunne annoncere en stor forbedring af vores Swiss Sovereign CRM-platform: REGEX-automatisering. REGEX står for Regular Expressions og er en metode til at identificere mønstre i tekst. I et CRM-miljø giver muligheden for at definere og anvende et mønster med regulære udtryk på tværs af kontaktoptegnelser og formularinput uovertruffen kontrol over datakvalitet, automatisering og tilpasning. Nogle tegn i REGEX har status som specialtegn, hvilket betyder, at de udfører specifikke funktioner. For at matche disse som bogstavelige tegn skal du undslippe dem med en backslash.
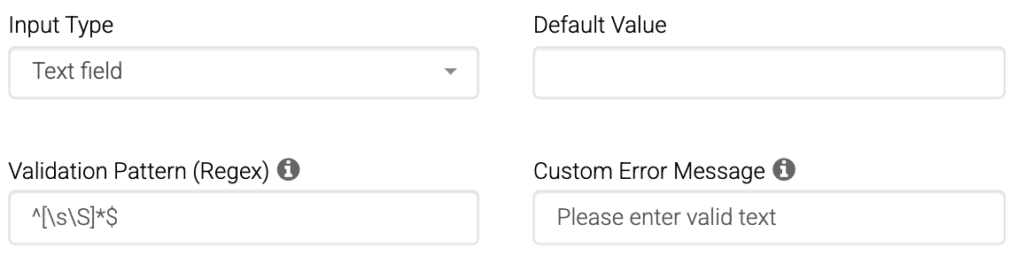
Uanset om du håndterer onboarding-formularer, kundenotater, transaktionsregistre eller lovpligtige data, Test af regulære udtryk lader dig definere forventede mønstre og håndhæve dem på tværs af alle input-streng. Med REGEX kan brugerne nu søge efter et eller flere tegn, validere alfabetiske tegn, identificere ikke-ciffer eller tegn uden mellemrum mønstre, og handle på matchede delstrenge. REGEX bruges ikke kun til validering, men også til søgende i teksten, så brugerne kan finde specifikke mønstre eller bogstavelig værdier i store datasæt.
Forståelse af regulære udtryk: En grundbog
A regulært udtryk er en Søgemønster bruges til at matche tegnkombinationer i strenge. Mønsteret fortolkes af regex-motorer, som behandler input-streng og identificere, om en match forekommer. I programmering bruger man typisk en funktion som RegExp-konstruktøren eller regex-metoder til at oprette og teste regulære udtryk i kode. Du kan anvende samme regulære udtryk til flere felter eller datasæt for at sikre konsistens og rene data.
Et par vigtige komponenter i regex-syntaks inkluderer:
- Karakterklasser: Definer sæt af tegn, der skal matches. For eksempel matcher [a-z] alle lille bogstav fra a til z.
- Ordtegn (\w): Matcher ethvert bogstav, ciffer eller understregningstegn.
- Tegn for mellemrum (\s): Matcher mellemrum og tabulatorer, form feed, Vognretur, linjeskift-tegn, og lodret fane.
- Tegn uden mellemrum (\S): Matcher alle tegn undtagen mellemrum.
- Backslash undslipper: Bruges til at give specialtegn a særlig betydning eller for at negere det (f.eks. . matcher en enkelt tegn periode).
- Firkantede parenteser: Bruges til at definere tegnsæt som [A-Za-z].
- Lodret bjælke (|): Fungerer som et logisk ELLER i udtryk.
- Indfangning af gruppe: Parenteser () grupperer mønstre og gemmer matchet tekst. Når en regex-funktion returnerer et resultat, inkluderer det ofte den matchede værdi eller delstreng, som kan bruges til yderligere behandling.
- Ikke-fangende gruppe: (?:...) grupperer mønstre uden at gemme matchet tekst.
- Ordets grænse (\b): Matcher positionen mellem et ordtegn og et ikke-ordtegn.
REGEX understøtter også Modifikatorer der påvirker matchende adfærd:
- g (global søgning): Matcher alle forekomster, ikke kun den første.
- i (Matchning uden forskel på store og små bogstaver): Skaber et match skelner ikke mellem store og små bogstaver.
- m (multiline-tilstand): Behandler strengen som flere linjer, hvilket påvirker ankre som ^ (begyndelse) og $ (slutningen af strengen).
- s (enkeltlinjetilstand): Giver . mulighed for at matche newline-tegn som linjefremføring, Vognretur, og newline-tegn.
Forståelse af karakterklasser
Tegnklasser er et grundlæggende element i regulære udtryk, som giver dig mulighed for at matche specifikke sæt af tegn i en streng. Defineres ved at omslutte tegn i firkantede parenteser “` [ ]
, Med en tegnklasse kan du angive præcis, hvilke tegn du vil matche. For eksempel kan tegnklassen ```[a-z]
matcher alle små bogstaver fra “a” til “z”, hvilket gør det nemt at ramme alfabetiske tegn i dine data.
Regulære udtryk giver også kortfattede tegnklasser for almindelige mønstre: “` \d
matcher ethvert ciffer, ```
\s
matcher ethvert tegn med hvidt mellemrum, og “` \w
matcher ethvert ordtegn (bogstaver, cifre eller understregninger). Hvis du har brug for at matche alle tegn undtagen dem i et sæt, kan du bruge en negeret tegnklasse ved at tilføje en karet, som ```
[^a-z]
, som matcher ethvert tegn, der ikke er et lille bogstav. Ved at kombinere tegnklasser med anden regex-syntaks kan du skabe kraftfulde udtryk til at validere, søge og rense dine CRM-data med præcision.
REGEX-brugsscenarier i InvestGlass
Her er eksempler på, hvordan REGEX øger produktiviteten i InvestGlass:
REGEX kan bruges til at validere inputfelter, filtrere data og handle på matchede understrenge. Derudover kan REGEX sikre et samlet match af et helt input, f.eks. ved at kræve, at et felt matcher et mønster fuldstændigt i stedet for kun delvist. Det er nyttigt, når du skal bekræfte, at hele inputstrengen er i overensstemmelse med et bestemt format, ikke kun en del af den.
Validering af data
Brug REGEX til at validere e-mailformater, håndhæve telefonnummerstruktur eller matche ASCII-tegn kun i brugernavne. Du kan f.eks. bruge mønsteret ^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+.[A-Za-z]{2,}$ til at validere e-mails. REGEX kan også bruges til at sikre, at inputfelter kun indeholder gyldige ord, eller til at kontrollere, om bestemte ord er til stede eller ikke i et felt.
Feltrensning med karakterklasser
Fjern overflødige mellemrum eller symboler ved hjælp af REGEX. Fjerne Klokkefigurer, normaliser afstanden med mellemrumstegn filtre, eller omformater felter ved hjælp af Indfangning af grupper og erstatninger. Efter rensningen sammenlignes det behandlede resultat med den oprindelige streng for at sikre, at kun de tilsigtede ændringer blev foretaget.
Avanceret filtrering og automatisering
Segmenter klienter, hvis navne starter med en bestemt lille bogstav, Det kan bruges til at matche dem, der indtaster særlige sekvenser, eller til at udløse arbejdsgange for felter, der mangler den forventede struktur. REGEX kan også bruges til at udtrække en værdi fra et felt, som derefter kan bruges til at udløse specifikke handlinger eller arbejdsgange. Dette muliggør automatiserede arbejdsgange på basis af Foregående element eller foregående punkt logik i stedet for manuel sortering.
Matchning på tværs af systemer
Ved at bruge samme udtryk På tværs af integrerede systemer opretholder du konsistens og nøjagtighed i klientmatchning og afstemning.
Sammenligning af REGEX-flavors
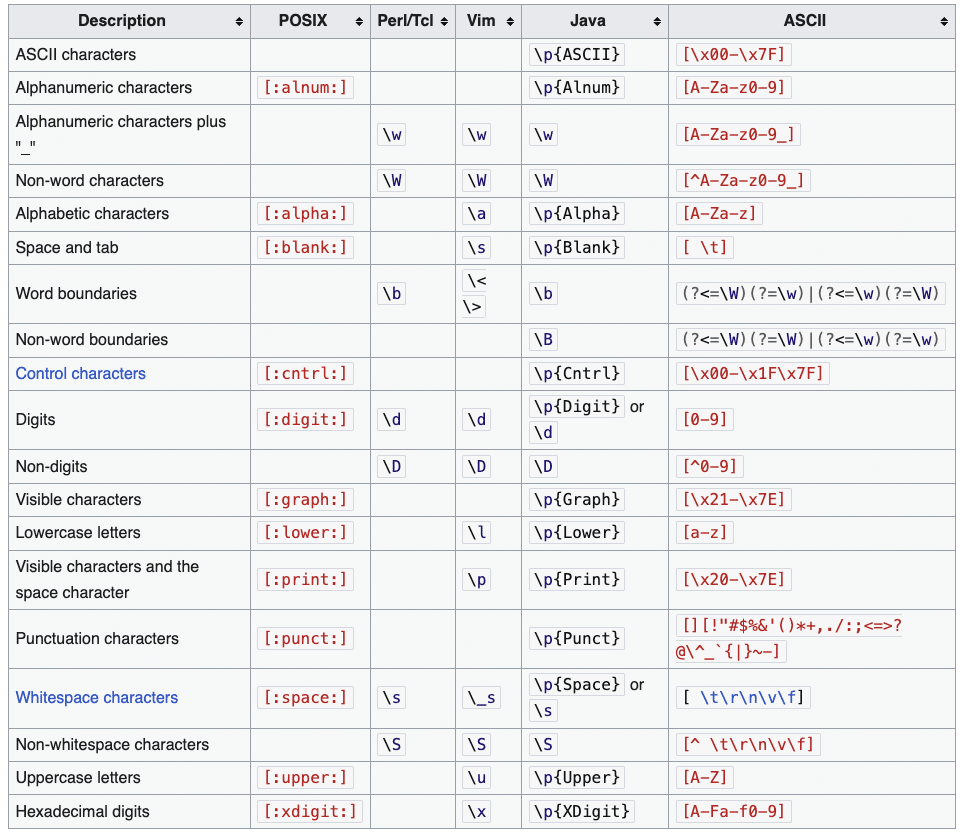
Anderledes regex-motorer fortolker syntaksen lidt anderledes. Selvom InvestGlass understøtter et bredt sæt af moderne REGEX-funktioner, er det vigtigt at forstå, at andre motorer (såsom JavaScript, Python eller .NET) kan behandle visse mønstre med variationer. Understøttelse af tegnsæt, f.eks. Unicode eller ASCII, kan også variere mellem motorer og påvirke, hvordan mønstre matches. Vi følger udbredte konventioner for at sikre kompatibilitet og intuitiv brug.
Se følgende tabel for en sammenligning af regex-funktioner og understøttelse af tegnsæt på tværs af motorer.
Bedste praksis for mønstermatchning
To get the most out of regular expressions in your CRM workflows, it’s important to follow best practices for pattern matching. Start by keeping your patterns as simple and concise as possible overly complex expressions can be hard to read and maintain. Leverage character classes to match specific groups of characters, and use quantifiers to control how many times a character or group should appear.
Indfangningsgrupper er uvurderlige til at udtrække specifikke dele af et match, mens ikke-indfangningsgrupper hjælper med at organisere dit mønster uden at gemme unødvendige data. Vær opmærksom på grådige kvantifikatorer, som nogle gange kan matche mere end beregnet og påvirke ydeevnen; overvej possessive kvantifikatorer for at begrænse backtracking, når det er nødvendigt. Frem for alt skal du altid teste dine regulære udtryk grundigt for at sikre, at de opfører sig som forventet med dine målstrenge. Ved at følge disse retningslinjer kan du skabe mønstre, der er robuste, effektive og nemme at administrere.
Almindelige fejl at undgå
Selv erfarne brugere kan løbe ind i problemer med regulære udtryk, hvis de ikke er forsigtige. En almindelig fejl er at glemme at undslippe specialtegn som “` .
eller ```
*
, hvilket kan få dit mønster til at matche utilsigtede tegn eller sekvenser. Forkert brug af tegnklasser eller kvantifikatorer kan også føre til forkerte matches, så det er vigtigt at forstå, hvordan hver del af dit mønster fungerer.
En anden faldgrube er unødvendig brug af indfangningsgrupper, som kan sænke ydeevnen og gøre dine resultater uoverskuelige. Brug i stedet ikke-indfangende grupper, når du ikke har brug for at udtrække en bestemt del af matchet. Hvis du ikke tester dine mønstre med en række forskellige inputstrenge, kan det resultere i uventet adfærd, så valider altid dine udtryk, før du implementerer dem. Endelig kan manglende udnyttelse af possessive quantifiers føre til ineffektiv matchning og problemer med ydeevnen. Ved at være opmærksom på disse almindelige fejl kan du skrive renere og mere pålidelige regulære udtryk til dine CRM-behov.
Tips og ressourcer
Vi har inkluderet et REGEX-snydeark, en hurtigreference og en komplet reference i InvestGlass' hjælpecenter, så brugerne kan opbygge, teste og anvende deres udtryk effektivt. Hvis du er i tvivl om, hvor du skal begynde, kan du starte med et onlineværktøj til at teste regex-matches mod din målstreng og derefter anvende udtrykket i din CRM-konfiguration. Disse platforme giver dig også mulighed for at teste regulære udtryk interaktivt, før du bruger dem i produktionen.
Bygget til suverænitet og tillid
InvestGlass er fortsat udelukkende hostet i Schweiz, hvilket giver vores kunder fuld kontrol over, hvor deres data befinder sig, skelner mellem store og små bogstaver optegnelser og compliance. Uanset om filtreringen er baseret på Ufølsomhed over for store og små bogstaver eller identificere mønstre på nuværende position af en post, giver vores REGEX-værktøj både fleksibilitet og præcision.
I takt med at data bliver mere komplekse, og forventningerne til rene, brugbare optegnelser stiger, regulære udtryk are no longer just for developers they are essential tools for CRM users, data managers, and regulators alike.
Fremtiden for mønstermatchning i CRM
Landskabet for mønstermatchning i CRM er i hastig udvikling, drevet af fremskridt inden for regulære udtryk, maskinlæring og naturlig sprogbehandling. Da CRM-systemer i stigende grad er afhængige af regulære udtryk til datavalidering, segmentering og automatisering, kan vi forvente endnu mere sofistikerede matchningsfunktioner. Integrationen af regulære udtryk med teknologier som enhedsgenkendelse og intentionsdetektering vil muliggøre smartere, kontekstbevidst databehandling.
Nye algoritmer, som f.eks. fuzzy og semantisk matching, vil yderligere forbedre nøjagtigheden og fleksibiliteten af mønstermatchning, så CRM-platforme bedre kan forstå og handle på komplekse kundedata. Brugervenlige grænseflader og intuitive værktøjer vil gøre det lettere for ikke-tekniske brugere at udnytte kraften i regulære udtryk og demokratisere adgangen til avancerede datastyringsfunktioner. I takt med at disse innovationer fortsætter, vil regulære udtryk forblive kernen i effektiv CRM og skabe bedre kundeoplevelser og forretningsresultater.
Er du klar til at komme i gang med regulat?
REGEX Automation is available now to all InvestGlass users. It allows you to bring structure to your data, logic to your workflows, and clarity to your records all while maintaining the privacy and sovereignty that define our platform.
Bed om en demo, eller udforsk vores vidensbase for eksempler, brugsscenarier og mønstre, der er klar til brug.


