Wofür wird Regex verwendet?

Warum REGEX im CRM wichtig ist
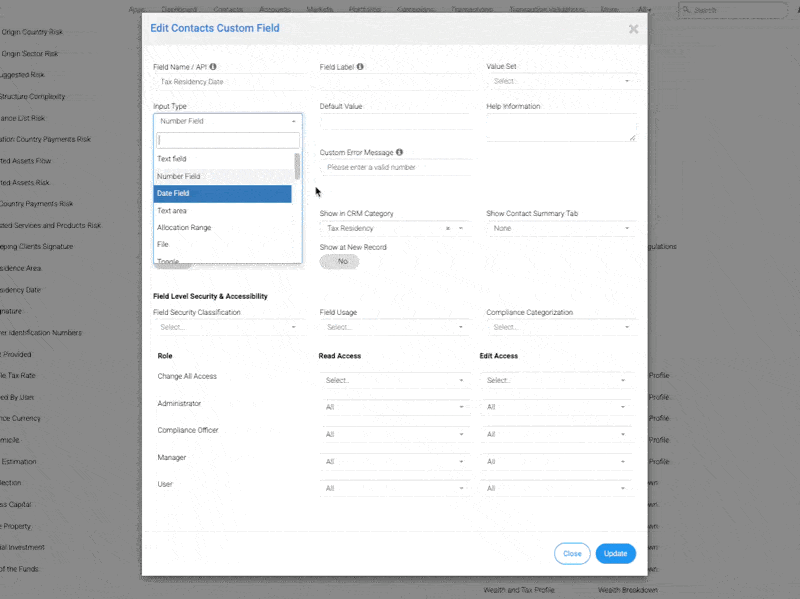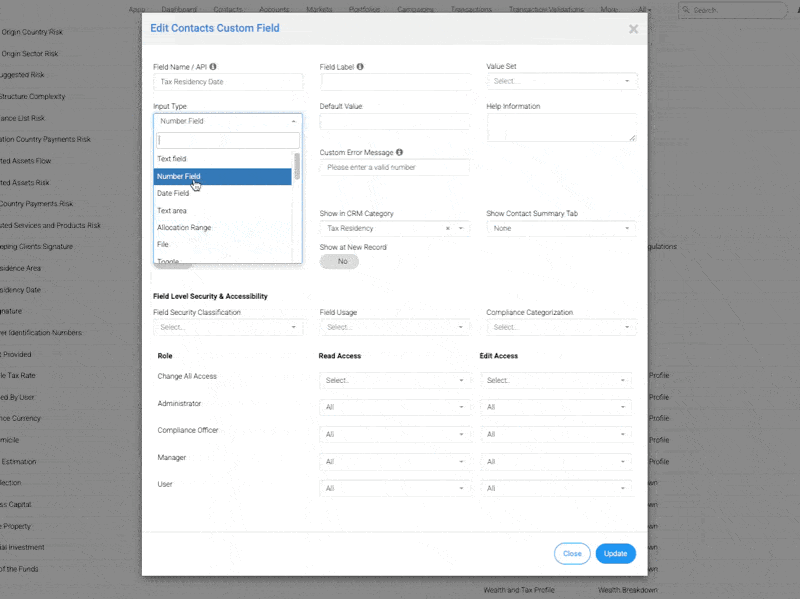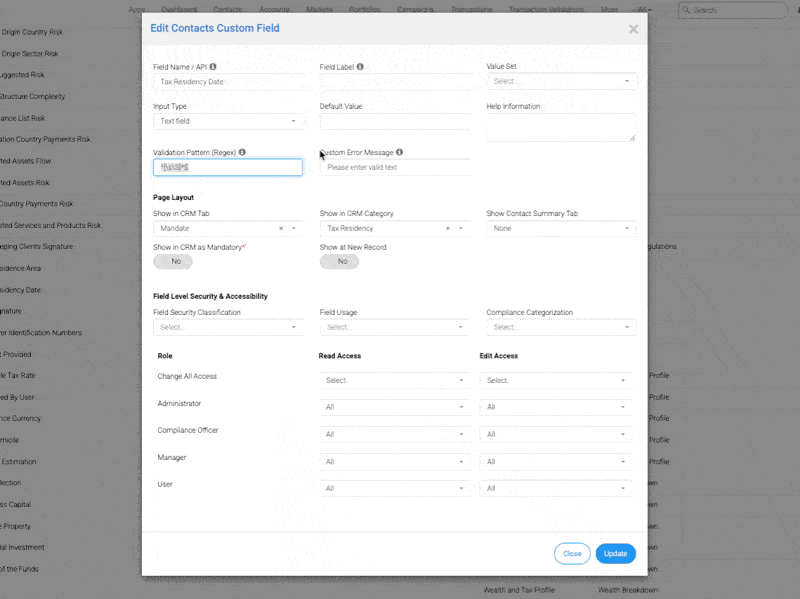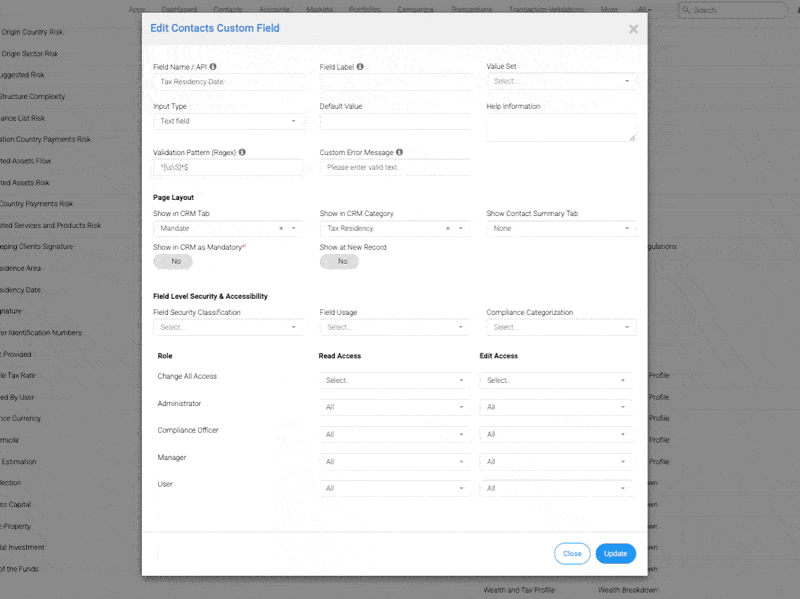
InvestGlass ist stolz darauf, eine wichtige Erweiterung unserer Swiss Sovereign CRM-Plattform anzukündigen: REGEX-Automatisierung. REGEX ist die Abkürzung für Reguläre Ausdrücke und ist eine Methode zur Identifizierung von Mustern in Texten. In einer CRM-Umgebung bietet die Möglichkeit, ein Muster für reguläre Ausdrücke zu definieren und auf Kontaktdatensätze und Formulareingaben anzuwenden, eine unübertroffene Kontrolle über Datenqualität, Automatisierung und Anpassung. Einige Zeichen in REGEX haben den Status eines Sonderzeichens, was bedeutet, dass sie bestimmte Funktionen erfüllen. Um sie als wörtliche Zeichen abzugleichen, müssen Sie sie mit einem Backslash abschließen.
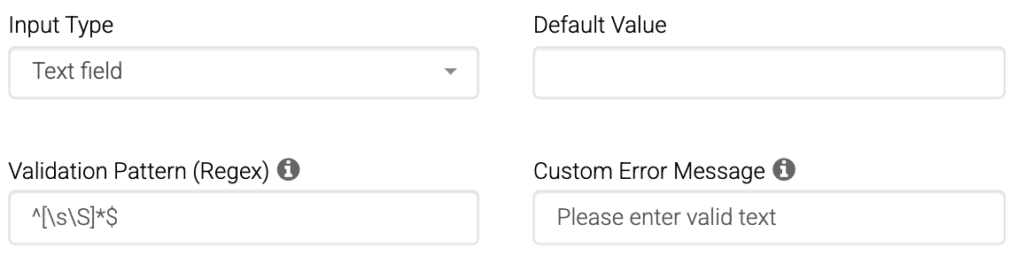
Ganz gleich, ob Sie Formulare für die Aufnahme von Kunden, Kundennotizen, Transaktionsdatensätze oder aufsichtsrechtliche Daten verwalten, Prüfung regulärer Ausdrücke können Sie erwartete Muster definieren und sie in jedem Bereich durchsetzen. Eingabestring. Mit REGEX können die Benutzer jetzt suchen nach ein oder mehrere Zeichen, validieren Alphabetische Zeichen, identifizieren ungerade oder Nicht-Whitespace-Zeichen Muster und handeln nach übereinstimmende Teilstrings. REGEX wird nicht nur für die Validierung verwendet, sondern auch für Suche innerhalb eines Textes, so dass die Benutzer bestimmte Muster oder wörtlich Werte in großen Datenbeständen.
Reguläre Ausdrücke verstehen: Eine Fibel
A regulärer Ausdruck ist eine Suchmuster verwendet, um Zeichenkombinationen in Zeichenketten zu finden. Das Muster wird interpretiert von Regex-Motoren, die die Eingabestring und erkennen, ob ein Spiel auftritt. In der Programmierung verwenden Sie normalerweise eine Funktion wie den RegExp-Konstruktor oder Regex-Methoden, um reguläre Ausdrücke im Code zu erstellen und zu testen. Sie können die gleicher regulärer Ausdruck auf mehrere Felder oder Datensätze anwenden, um Konsistenz und saubere Daten zu gewährleisten.
Einige wichtige Bestandteile von Regex-Syntax umfassen:
- Charakterklassen: Definieren Sie die zu übereinstimmenden Zeichensätze. Zum Beispiel passt [a-z] auf alle Kleinbuchstabe von von A bis Z.
- Wortzeichen (\w): Entspricht einem beliebigen Buchstaben, einer Ziffer oder einem Unterstrich.
- Whitespace-Zeichen (\s): Passt zu Leerzeichen und Tabulatoren, Formularvorschub, Wagenrücklauf, Zeilenvorschubzeichen, und vertikale Registerkarte.
- Nicht-Whitespace-Zeichen (\S): Passt auf jedes Zeichen außer Leerzeichen.
- Backslash entweicht: Verwendet, um die Sonderzeichen a besondere Bedeutung oder zu negieren (z. B. . entspricht einem Einzelzeichen Zeitraum).
- Eckige Klammern: Dient zur Definition von Zeichensätze wie [A-Za-z].
- Senkrechter Balken (|): Wirkt in Ausdrücken wie ein logisches ODER.
- Erfassen der Gruppe: Klammern () gruppieren Muster und speichern den übereinstimmenden Text. Wenn eine Regex-Funktion ein Ergebnis zurückgibt, enthält es oft den übereinstimmenden Wert oder die Teilzeichenkette, die für die weitere Verarbeitung verwendet werden kann.
- Nicht erfassende Gruppe: (?:...) gruppiert Muster, ohne den übereinstimmenden Text zu speichern.
- Wort-Grenze (\b): Entspricht der Position zwischen einem Wortzeichen und einem Nicht-Wortzeichen.
REGEX unterstützt auch Modifikatoren die das Anpassungsverhalten beeinflussen:
- g (globale Suche): Passt auf alle Instanzen, nicht nur auf die erste.
- i (Abgleich ohne Berücksichtigung der Groß-/Kleinschreibung): Ermöglicht das Spiel Groß- und Kleinschreibung wird nicht berücksichtigt.
- m (Mehrzeilenmodus): Behandelt die Zeichenkette als mehrere Zeilen, was sich auf Anker wie ^ (Anfang) und $ (Ende der Zeichenkette).
- s (Einzelzeilenmodus): Ermöglicht . die Übereinstimmung mit Zeilenumbrüchen wie Zeilenvorschub, Wagenrücklauf, und Zeilenumbruchzeichen.
Verstehen der Charakterklassen
Zeichenklassen sind ein grundlegendes Element regulärer Ausdrücke, das Ihnen die Möglichkeit gibt, bestimmte Zeichensätze in einer Zeichenkette zu finden. Definiert durch das Einschließen von Zeichen in eckigen Klammern “` [ ]
, Mit einer Zeichenklasse können Sie genau angeben, welche Zeichen Sie abgleichen wollen. Zum Beispiel kann die Zeichenklasse ````[a-z]
passt auf jeden Kleinbuchstaben von “a” bis “z”, so dass es einfach ist, alphabetische Zeichen in Ihren Daten zu finden.
Reguläre Ausdrücke bieten auch Kurzzeichen-Klassen für gängige Muster: “` \d
passt auf jede Ziffer, ```
\s
passt auf ein beliebiges Leerzeichen, und “` \w
passt auf jedes Wortzeichen (Buchstaben, Ziffern oder Unterstriche). Wenn Sie ein beliebiges Zeichen mit Ausnahme derjenigen in einer Menge abgleichen müssen, können Sie eine negierte Zeichenklasse verwenden, indem Sie ein Caret hinzufügen, z.B. ```
[^a-z]
, die auf jedes Zeichen passt, das kein Kleinbuchstabe ist. Durch die Kombination von Zeichenklassen mit anderer Regex-Syntax können Sie leistungsstarke Ausdrücke erstellen, um Ihre CRM-Daten präzise zu validieren, zu suchen und zu bereinigen.
REGEX Anwendungsfälle in InvestGlass
Hier sind Beispiele dafür, wie REGEX die Produktivität in InvestGlass steigert:
REGEX kann verwendet werden, um Eingabefelder zu überprüfen, Daten zu filtern und auf übereinstimmende Teilstrings zu reagieren. Außerdem kann REGEX eine Gesamtübereinstimmung einer gesamten Eingabe sicherstellen, z. B. dass ein Feld vollständig und nicht nur teilweise mit einem Muster übereinstimmen muss. Dies ist nützlich, wenn Sie bestätigen müssen, dass die gesamte Eingabekette einem bestimmten Format entspricht und nicht nur ein Teil davon.
Validierung von Daten
Verwenden Sie REGEX, um E-Mail-Formate zu validieren, die Struktur von Telefonnummern zu erzwingen oder um ASCII-Zeichen nur in Benutzernamen. Sie könnten zum Beispiel das Muster ^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+.[A-Za-z]{2,}$ verwenden, um E-Mails zu überprüfen. REGEX kann auch verwendet werden, um sicherzustellen, dass Eingabefelder nur gültige Wörter enthalten, oder um zu prüfen, ob bestimmte Wörter in einem Feld vorhanden sind oder nicht.
Feldbereinigung mit Charakterklassen
Eliminieren Sie überflüssige Leerzeichen oder Symbole mit REGEX. entfernen Glockenzeichen, normalisieren Sie die Abstände mit Whitespace-Zeichen Filter, oder formatieren Sie Felder mit Erfassungsgruppen und Ersetzungen. Vergleichen Sie nach der Bereinigung das verarbeitete Ergebnis mit der ursprünglichen Zeichenfolge, um sicherzustellen, dass nur die beabsichtigten Änderungen vorgenommen wurden.
Erweiterte Filterung und Automatisierung
Segmentieren Sie Kunden, deren Namen mit einem bestimmten Kleinbuchstabe, Die REGEX kann auch verwendet werden, um die Eingabe spezieller Sequenzen abzugleichen oder um Workflows für Felder auszulösen, die nicht die erwartete Struktur aufweisen. REGEX kann auch verwendet werden, um einen Wert aus einem Feld zu extrahieren, der dann zum Auslösen bestimmter Aktionen oder Workflows verwendet werden kann. Dies ermöglicht die Automatisierung von Arbeitsabläufen auf der Grundlage von vorhergehendes Element oder vorangegangene Position Logik, anstatt einer manuellen Sortierung.
Systemübergreifender Abgleich
Durch die Verwendung des gleicher Ausdruck über integrierte Systeme hinweg sorgen Sie für Konsistenz und Genauigkeit bei Kundenabgleich und -abstimmung.
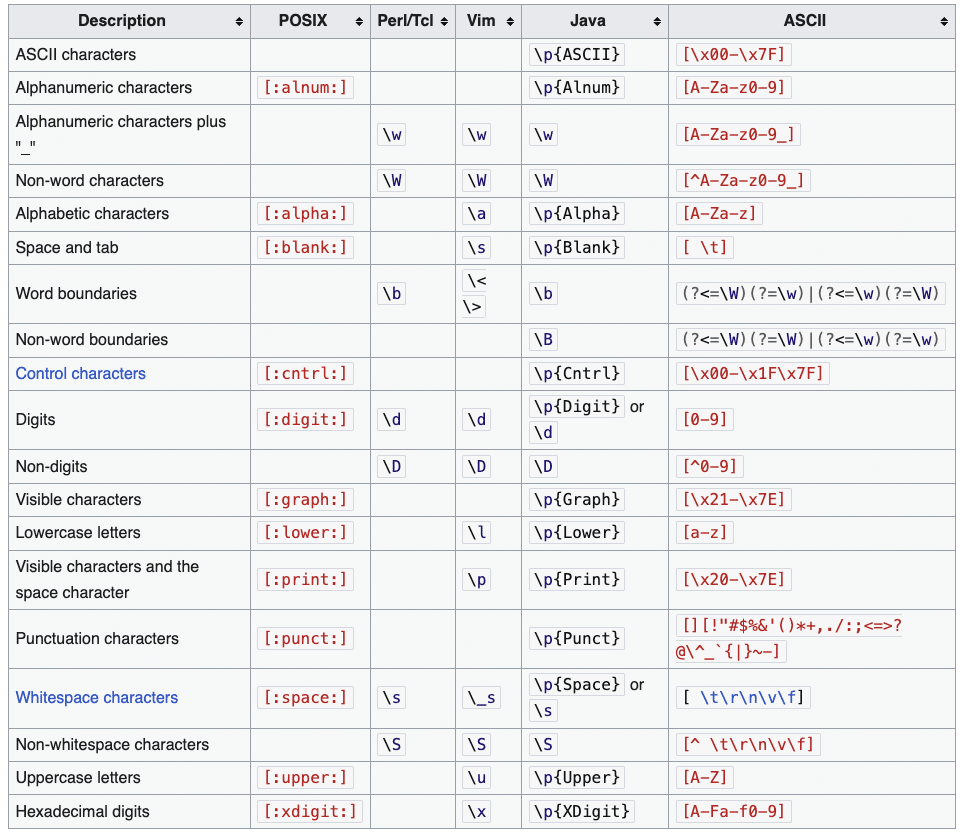
Vergleich der REGEX-Geschmacksrichtungen
Anders Regex-Motoren interpretieren die Syntax etwas anders. Obwohl InvestGlass eine breite Palette moderner REGEX-Funktionen unterstützt, ist es wichtig zu verstehen, dass andere Motoren (z. B. JavaScript, Python oder .NET) können bestimmte Muster unterschiedlich behandeln. Auch die Unterstützung von Zeichensätzen wie Unicode oder ASCII kann sich zwischen den Engines unterscheiden, was sich auf den Abgleich von Mustern auswirkt. Wir halten uns an weit verbreitete Konventionen, um Kompatibilität und intuitive Nutzung zu gewährleisten.
Einen Vergleich der Regex-Funktionen und der Zeichensatzunterstützung der verschiedenen Engines finden Sie in der folgenden Tabelle.
Bewährte Praktiken für den Musterabgleich
Um reguläre Ausdrücke in Ihren CRM-Workflows optimal nutzen zu können, ist es wichtig, bewährte Verfahren für den Musterabgleich zu befolgen. Beginnen Sie damit, Ihre Muster so einfach und prägnant wie möglich zu halten - zu komplexe Ausdrücke können schwer zu lesen und zu pflegen sein. Nutzen Sie Zeichenklassen, um bestimmte Gruppen von Zeichen abzugleichen, und verwenden Sie Quantifizierer, um zu steuern, wie oft ein Zeichen oder eine Gruppe vorkommen soll.
Erfassende Gruppen sind von unschätzbarem Wert, um bestimmte Teile einer Übereinstimmung zu extrahieren, während nicht-erfassende Gruppen helfen, Ihr Muster zu organisieren, ohne unnötige Daten zu speichern. Achten Sie auf gierige Quantifizierer, die manchmal mehr als beabsichtigt übereinstimmen und die Leistung beeinträchtigen können; ziehen Sie possessive Quantifizierer in Betracht, um bei Bedarf das Backtracking zu begrenzen. Vor allem aber sollten Sie Ihre regulären Ausdrücke immer gründlich testen, um sicherzustellen, dass sie sich bei den Zielzeichenketten wie erwartet verhalten. Wenn Sie diese Richtlinien befolgen, werden Sie Muster erstellen, die robust, effizient und einfach zu verwalten sind.
Häufig zu vermeidende Fehler
Selbst erfahrene Benutzer können mit regulären Ausdrücken Probleme bekommen, wenn sie nicht vorsichtig sind. Ein häufiger Fehler ist das Vergessen von Sonderzeichen wie “` .
oder ````
*
, was dazu führen kann, dass Ihr Muster mit unbeabsichtigten Zeichen oder Sequenzen übereinstimmt. Die falsche Verwendung von Zeichenklassen oder Quantifizierern kann ebenfalls zu falschen Übereinstimmungen führen, daher ist es wichtig zu verstehen, wie jeder Teil Ihres Musters funktioniert.
Ein weiterer Fallstrick ist die unnötige Verwendung von Erfassungsgruppen, die die Leistung verlangsamen und Ihre Ergebnisse unübersichtlich machen können. Verwenden Sie stattdessen nicht-erfassende Gruppen, wenn Sie einen bestimmten Teil der Übereinstimmung nicht extrahieren müssen. Wenn Sie Ihre Muster nicht mit einer Vielzahl von Eingabestrings testen, kann dies zu unerwartetem Verhalten führen, daher sollten Sie Ihre Ausdrücke immer validieren, bevor Sie sie einsetzen. Und schließlich kann die Nichtnutzung von Possessivquantoren zu ineffizienten Übereinstimmungen und Leistungsproblemen führen. Wenn Sie sich dieser häufigen Fehler bewusst sind, können Sie sauberere und zuverlässigere reguläre Ausdrücke für Ihre CRM-Anforderungen schreiben.
Tipps und Ressourcen
Wir haben einen REGEX-Spickzettel, eine Kurzreferenz und eine vollständige Referenz in das InvestGlass-Hilfezentrum aufgenommen, damit Benutzer ihre Ausdrücke effektiv erstellen, testen und anwenden können. Wenn Sie sich nicht sicher sind, wo Sie anfangen sollen, beginnen Sie mit einem Online-Tool, um Regex-Treffer gegen Ihre Zielzeichenfolge zu testen, und wenden Sie diesen Ausdruck dann in Ihrer CRM-Konfiguration an. Diese Plattformen ermöglichen es Ihnen auch, reguläre Ausdrücke interaktiv zu testen, bevor Sie sie in der Produktion verwenden.
Gebaut für Souveränität und Vertrauen
InvestGlass wird vollständig in der Schweiz gehostet, so dass unsere Kunden die volle Kontrolle über den Aufenthaltsort ihrer Daten haben, Groß- und Kleinschreibung Aufzeichnungen und Compliance. Ob Filterung auf Basis von Unempfindlichkeit gegenüber Groß- und Kleinschreibung oder das Erkennen von Mustern auf der aktuelle Position eines Eintrags bietet unser REGEX-Tool sowohl Flexibilität als auch Präzision.
Die Daten werden immer komplexer und die Erwartungen an saubere, verwertbare Datensätze steigen, reguläre Ausdrücke sind nicht mehr nur für Entwickler, sondern auch für CRM-Anwender, Datenverwalter und Regulierungsbehörden unverzichtbare Werkzeuge.
Die Zukunft des Musterabgleichs im CRM
Die Landschaft des Musterabgleichs im CRM entwickelt sich rasant weiter, angetrieben von Fortschritten bei regulären Ausdrücken, maschinellem Lernen und der Verarbeitung natürlicher Sprache. Da sich CRM-Systeme zunehmend auf reguläre Ausdrücke für die Datenvalidierung, Segmentierung und Automatisierung verlassen, können wir mit noch ausgefeilteren Abgleichsfunktionen rechnen. Die Integration von regulären Ausdrücken mit Technologien wie Entity Recognition und Intent Detection wird eine intelligentere, kontextbezogene Datenverarbeitung ermöglichen.
Neue Algorithmen wie der unscharfe und semantische Abgleich werden die Genauigkeit und Flexibilität des Musterabgleichs weiter verbessern und es CRM-Plattformen ermöglichen, komplexe Kundendaten besser zu verstehen und darauf zu reagieren. Benutzerfreundliche Schnittstellen und intuitive Tools werden es auch technisch nicht versierten Anwendern erleichtern, die Leistungsfähigkeit regulärer Ausdrücke zu nutzen und den Zugang zu fortschrittlichen Datenmanagementfunktionen zu demokratisieren. Da diese Innovationen weitergehen, werden reguläre Ausdrücke auch in Zukunft das Herzstück eines effektiven CRM bilden und zu besseren Kundenerfahrungen und Geschäftsergebnissen beitragen.
Sind Sie bereit, mit regulat anzufangen?
REGEX Automation ist jetzt für alle InvestGlass-Nutzer verfügbar. Sie ermöglicht es Ihnen, Struktur in Ihre Daten zu bringen, Logik in Ihre Arbeitsabläufe und Klarheit in Ihre Aufzeichnungen - und das alles unter Wahrung der Privatsphäre und Souveränität, die unsere Plattform ausmachen.
Fordern Sie eine Demo an oder erkunden Sie unsere Wissensdatenbank mit Beispielen, Anwendungsfällen und fertigen Mustern.